Nell’ultima edizione di DataScienceSeed Online prima della pausa estiva, Mercoledi 21 Luglio alle18:00 abbiamo parlato di Edge Computing, con Alberto Cabri, PhD.
Se hai partecipato o se hai visto il video (che trovi qui sotto) dacci un feedback!
La disponibilità di piattaforme integrate ad alte prestazioni consente al giorno d’oggi di eseguire algoritmi in edge con indubbi vantaggi sul consumo di banda, la sicurezza e la salvaguardia della privacy. Tuttavia la strada non è in discesa e talvolta la complessità di rendere operativo un sistema edge non è trascurabile e si deve lavorare su sistemi eterogenei con strumenti che se da un lato possono semplificare la realizzazione ed il deployment delle soluzioni (ad. es. docker) dall’altro richiedono l’acquisizione di ulteriori competenze.
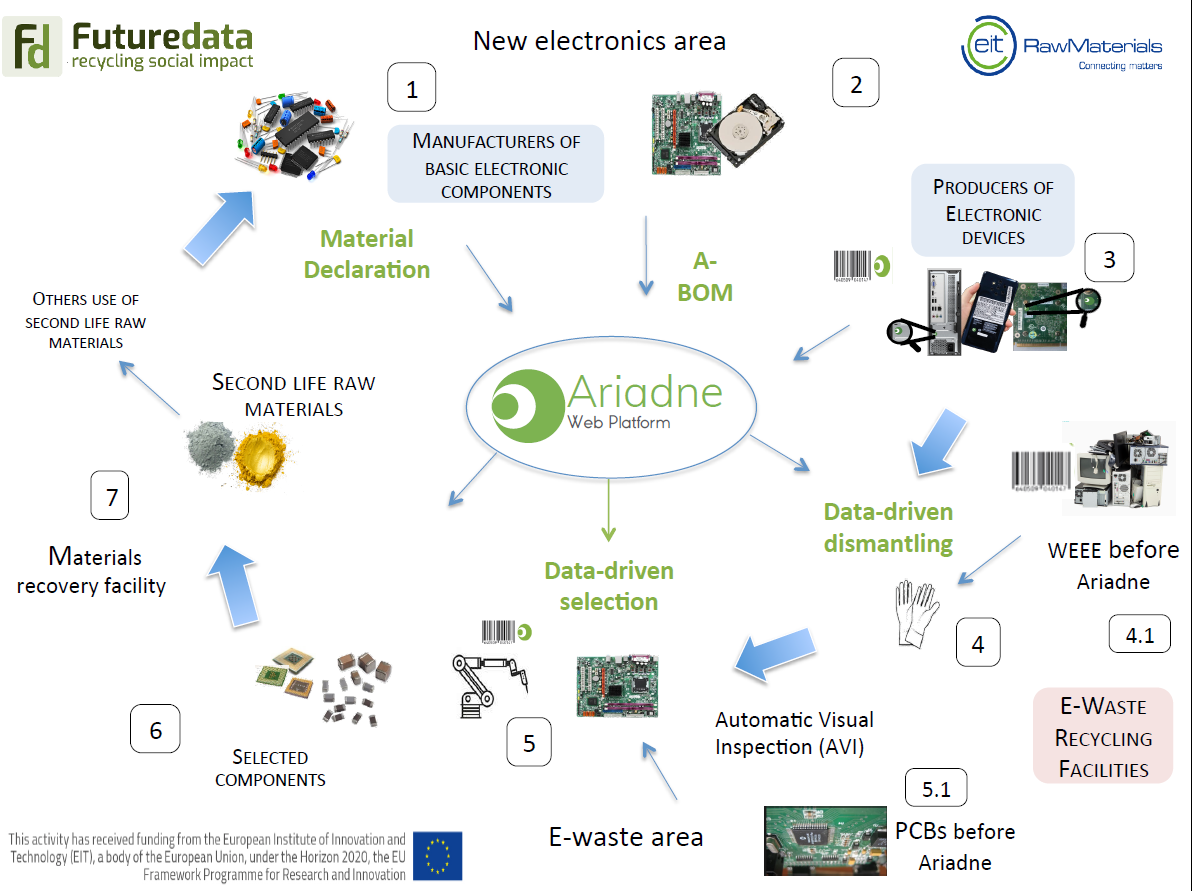
Il caso d’uso mostrato è relativo al riconoscimento real-time di componenti elettronici con deep learning, legato al progetto Ariadne, Data Driven Recovery System, di cui ci ha raccontato i sommi capi Rosario Capponi nella sessione di Q&A.
Alberto Cabri Ha conseguito il Dottorato in Computer Science and Systems Engineering presso l’Università di Genova nel 2020. E’ un socio fondatore di Vega Research Laboratories, uno spin-off dell’Università di Genova la cui mission sono la progettazione e sviluppo di soluzioni basate su tecnologie emergenti, quali AI, edge computing. Ha una Laurea in Ingegneria Elettronica ed è docente di ruolo di Informatica presso un Istituto Tecnico di Genova. E’ stato fondatore ed AD di Flashover Time S.r.l., Manager in Computer Science Corporation, Project Manager in Marconi Communications e ha ricoperto diversi ruoli tecnici in Elsag e Cap Gemini.
Ecco l’agenda del quinto incontro, tutto legato ad attività di ricerca tra Digitale, Arte e Beni Culturali
In Codice Ratio: trascrizione automatica di manoscritti medievali
Simone Scardapane: Ricercatore @ Università La Sapienza e Presidente IAML
Il progetto di ricerca In Codice Ratio, promosso da un team di Roma Tre, si pone l’obiettivo di sviluppare tecnologie per l’estrazione automatica dell’informazione da documenti storici, a partire da un caso di studio d’eccezione: l’Archivio Segreto Vaticano, uno dei più grandi archivi storici al mondo in termini di dimensioni e valore dei documenti custoditi. L’analisi di documenti così antichi presenta una serie di sfide specifiche: i testi sono manoscritti, in lingua latina ed accessibili unicamente in forma di immagine. Nel talk si descrivono i risultati ottenuti finora, i problemi da affrontare nel futuro, e soprattutto come le più recenti tecniche di deep learning (reti convolutive, U-Net, sistemi sequence2sequence) aiutano e guidano nella possibile risoluzione di queste sfide.
Presentazione di Simone Scardapane in formato pdf
Metodi e Modelli 3D per l’analisi, la classificazione e l’interpretazione di reperti archeologici
Per rispondere alla crescente necessità di metodi per la quantificazione della similarità tra frammenti e l’identificazione di elementi stilisticamente compatibili, IMATI ha sviluppato tecniche di analisi, classificazione e riconoscimento di forma, che vanno dall’identificazione di caratteristiche geometriche peculiari di un gruppo di oggetti, al riconoscimento di particolari configurazioni o strutture, fino all’identificazione e classificazione di parti con particolari decori e funzionalità. A partire da tali premesse è stata sviluppata una ricca base metodologica per la classificazione, la ricerca e il confronto di oggetti attraverso similarità di forma, declinando il concetto di similarità rispetto alle diverse sfaccettature che tale termine suggerisce: similarità geometrica, strutturale, funzionale o semantica.
La classificazione, la riunificazione e il riconoscimento di frammenti e decorazioni sono argomenti trattati nel progetto Horizon 2020 GRAVITATE.
Presentazione di Bianca Falcidieno e Silvia Biasotti in formato pdf
Nel primo incontro abbiamo conosciuto aziende che lavorano nel campo data science e machine learning ed abbiamo cominciato a conoscere gli strumenti per cimentarsi in queste discipline.
Nel secondo incontro, ospitato dal Digital Tree Innovation Habitat, abbiamo cominciato invece a bagnarci i piedi negli algoritmi, sempre restando legati a problemi concreti.
Il primo speaker è stato Alberto Cabri, di Vega Research Labs, che ci ha presentato un caso di classificazione in ambito automotive, e di come è stato risolto con strumenti open source, generando infine un efficiente modello white box che consente la classificazione della tipologia di motori sulla linea di produzione.
Tramite questo link si può scaricare un file .zip contenente il dataset ed il notebook mostrato da Alberto, in versione eseguibile o in versione pdf per la sola consultazione
Marco Tagliavacche è il presidente dell’associazione Architecta (https://www.architecta.it/) e ci ha parlato dell’importanza dell’organizzazione e della visualizzazione dei dati. Non di solo codice vive il data scientist!
La presentazione è disponibile in pdf a questo link.
Per finire, Giorgio Garziano, Senior SW developer, e autore su http://www.datascienceplus.com ci ha presentato i risultati della sua analisi sul dataset di Cynomys, il caso di Smart Farming presentato tra i challenge nel primo incontro che trovate alla pagina:
Il lavoro di Giorgio è stato presentato insieme a Fabiana Surace, founder di Cynomys, che ha riassunto il problema e ne ha spiegato molto chiaramente il valore di business per gli allevatori
La documentazione completa è a questo link, dal quale si scarica un .zip con la presentazione di Fabiana in pdf ed il file HTML con l’analisi di Giorgio. Il file HTML va visualizzato con connessione internet attiva per visualizzare correttamente le formule.
Se ti interessa dare un’occhiata ai dataset relativi ai challenge, contattaci. Se la tua analisi sarà particolarmente interessante uno degli interventi del prossimo incontro potrebbe essere il tuo!
Se ti interessa dare un’occhiata ai dataset relativi ai challenge, per esplorarli nel tempo che manca al maeetup contattaci. Se la tua analisi sarà particolarmente interessante uno degli interventi dei prossimi incontri potrebbe essere il tuo!
Data Science, Machine Learning, Intelligenza Artificiale…
Dietro alle parole ci sono opportunità di crescita, per chi vuole imparare ed essere operativo e per chi ha capito che per sviluppare la propria attività la via è quella dei dati. I meetup DataScienceSeed nascono per unire questi due mondi, con l’aiuto di chi sta già percorrendo queste strade.
Per chi vuole imparare è una occasione di sperimentare come diventare operativi sia possibile con strumenti accessibili e senza bisogno di essere guru.
Per chi vuole sviluppare la propria attività per comprendere le opportunità, orientarsi ed incontrare chi potrebbe essere d’aiuto.
In questo primo incontro abbiamo conosciuto tre persone speciali nel campo del Data Science: un manager di una azienda nata a Genova nel campo del Machine Learning e che è ora basata a Boston tra i grandi dell’AI, un imprenditore appassionato di programmazione ed ora di machine learning, che sta affrotando con decisione la metamorfosi verso questo nuovo mondo, ed una Data Scientist con la vocazione dell’Open Source che attraverso la sua esperienza professionali e di attività nelle conferenze della community Python, ci ha guidati in una carrellata tra gli strumenti disponibili per imparare ed affrontare la sfida dei dati.
Ecco (quasi tutti) i relatori e gli organizzatori: da sinistra Marcello Morchio (DataScienceSeed), Andrea Rapuzzi (A-Sign), Stefania Delprete (TOP-IX), Andrea Caridi (Rulex), Luca Oppo (Madein.it), Franco De Mattei (DataScienceSeed, Maker’s Village) – Missing: Enrico Carta (Cynomys), Enrico Ferrari (Rulex)
Enrico Ferrari, R&D Manager, Rulex Enrico si occupa di machine learning da più di 10 anni. Ha partecipato dagli inizi all’avventura di Rulex, una startup nata dalla ricerca genovese con l’obiettivo di produrre modelli predizioni spiegabili e da qualche anno sbarcata a Boston. Per Enrico il futuro dell’Intelligenza Artificiale è nel Cognitive Machine Learning che combina la potenza delle macchine con le capacità di interpretazione e di intuizione degli umani.
Andea Rapuzzi, Owner A-Sign Da software engineering a data science, quanto è lungo il passo? Andrea Rapuzzi ci racconta il suo viaggio alla scoperta di una nuova prospettiva e di un set di skill indispensabile per affrontare le nuove sfide tecnologiche. Perché farlo? Da dove partire? Con quali competenze iniziali? Quanto impegno richiede? Dove si può arrivare? Non un manuale di navigazione ma il diario di bordo di due anni entusiasmanti.
Stefania Delprete, Data scientist, TOP-IX, Personal development expert Stefania è coinvolta nella comunità open source e di data science come volontaria alla PyCon, EuroPython, NumFOCUS ambassador, e organizzando a Torino la Pandas Sprint prendendo parte ad un evento internazionale.
Stefania ha esposto, anche con una demo basata su open data di Genova, come si possa far leva sulle librerie open source di Python, la loro documentazione e interazione con la comunità per iniziare alla grande il tuo progetto di data science!
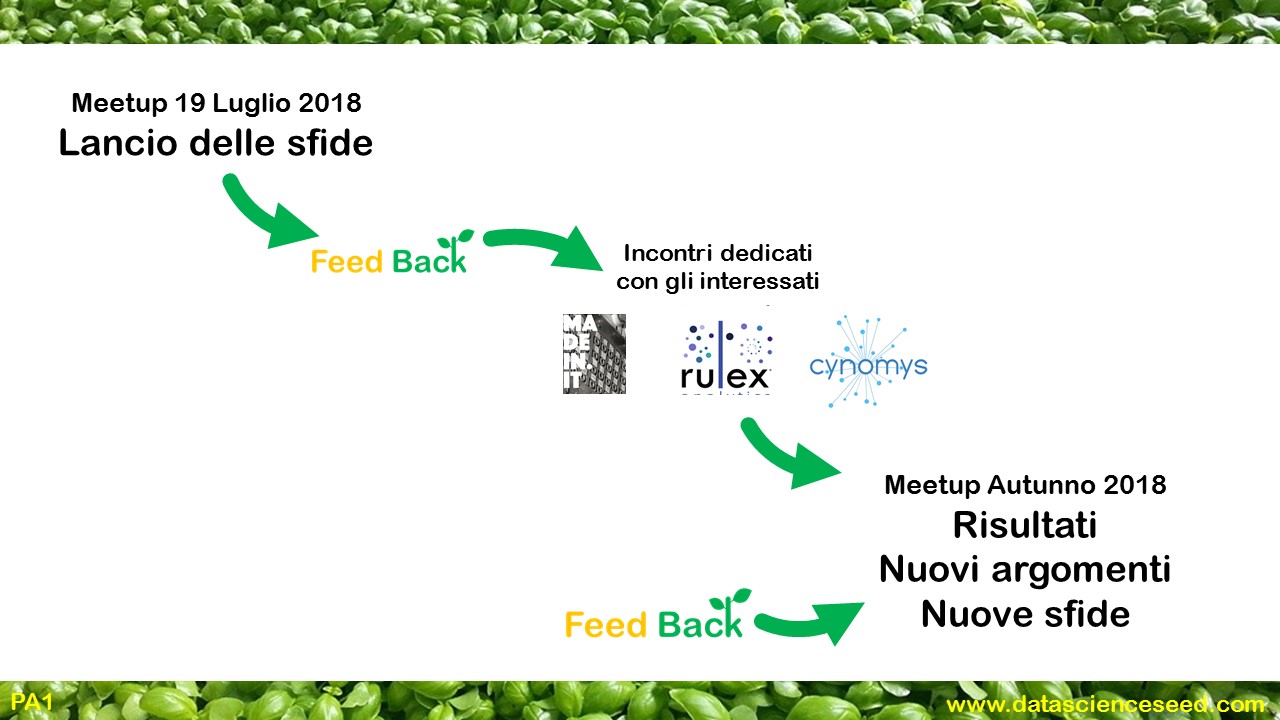
Ecco le prime sfide, per mettere alla prova le nostre competenze di Data Science su problemi concreti. In base all’interesse raccolto tra i partecipanti organizzeremo incontri dedicati all’approfondimento dei tre problemi ed alle modalità per affrontarli. Nel prossimo meetup vedremo se sarà uscito qualcosa di interessante!
Se hai partecipato all’evento, puoi dare feedback e segnalarci un eventuale interesse, senza impegno, per appronfondire una o più sfide, usando questo link.
Se non hai partecipato all’evento ma ti piacciono le sfide, usa questo link.
Incantastorie 2018
un Dataset in movimento – presentato da Luca Oppo, Madein.it
Download slides – Challenge Madein.it
Musica Online: studiamo il “churning” di un servizio online
Presentato da Andrea Caridi, Rulex
Download slide – Challenge Rulex
Allevamento sostenibile: la tecnologia nella stalla
presentato da Enrico Carta, Cynomys
Download slides – Challenge Cynomys
Abbiamo concluso la serata con un aperitivo di networking, con prodotti di Aggio House
DataScienceSeed è un meetup NO PROFIT, sostenibile grazie alla sponsorizzazione di imprenditori illuminati, dalla disponibilià di speakers competenti con la passione per la condivisione ed all’interesse di un pubblico vivace ed interessato. Se fai parte di una di queste categorie puoi entra nella community Data Science Seed