

Di seguito l’agenda dell’ottavo DataScienceSeed meetup di Martedi 1 Ottobre
Se hai partecipato, lasciaci un feedback!

Evoluzione di Interfacce Vocali
Il trend delle interfacce uomo macchina punta ad un sempre maggiore utilizzo di sistemi basati su voce, recentemente popolarizzati anche grazie alla diffusione di “smart speakers” di successo commerciale. La voce permette di ridurre l’attrito sperimentato dagli utenti in termini di interazioni uomo-macchina, non richiedendo attenzione esclusiva da parte dell’utilizzatore e permettendo sempre più spesso l’utilizzo di un linguaggio naturale.
Dotvocal basa su questo modo naturale di comunicare le proprie soluzioni vocali e multimodali, nelle quali l’azienda può vantare tra le più importanti realizzazioni in campo nazionale ed internazionale. La peculiare trasversalità delle tecnologie vocali ha permesso a Dotvocal di sviluppare soluzioni per molti clienti in svariati settori: piattaforme di infotainment in ambito automotive, funzionalità di traduzioni linguistiche, gestione di portali telefonici automatici per società di trasporti e logistica, oltre ad aver sviluppato un proprio prodotto completamente innovativo nell’ambito degli ausili per disabili, che permette di fruire dei contenuti del PC e di Internet usando in modo semplice i comandi vocali.
Enrico Reboscio è fondatore e CEO di DotVocal e ci ha raccontato la sua esperienza nell’evoluzione di questa tecnologia, del relativo mercato e delle opportunità e dellesfide che si prospettano.
Le slide di Enrico sono a questo link (pdf 1.2M)
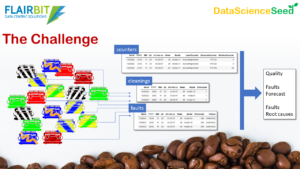
Per ricevere le credenziali di accesso al dataset presentato da Enrico alla fine del talk, compila il form qui sotto

Strategia Nazionale AI
Marco Bressani ci ha parlato della sua esperienza come membro del gruppo di esperti di alto livello selezionati dal Ministero dello Sviluppo Economico per elaborare la strategia nazionale sull’Intelligenza Artificiale e contribuire al Piano Coordinato promosso dalla Commissione Europea. I trenta superesperti sono stati selezionati tra esponenti del mondo imprenditoriale, delle associazioni di categoria, del mondo della ricerca, dell’università e della società civile con gli obiettivi di conoscere, approfondire ed affrontare il tema dell’Intelligenza Artificiale, valorizzare la ricerca, l’educazione e la formazione, nonché attrarre e favorire gli investimenti pubblici e privati. L’Italia punta ad avere un ruolo di avanguardia in Europa in questo settore strategico, considerato un’opportunità senza precedenti per incrementare la produttività del lavoro e per consentire progressi straordinari verso lo sviluppo sostenibile, senza perdere di vista i rischi derivanti da evantuali usi “incauti” dell’AI. Il lavoro del gruppo si è concluso lo scorso maggio con la pubblicazione di un paper di oltre 100 pagine dal titolo “Proposte per una strategia italiana per l’Intelligenza artificiale”, è ora all’attenzione dei tecnici del Ministero.
Marco Bressani, imprenditore e consulente di direzione, è fondatore e amministratore di Digital Tree, ecosistema dedicato alla creazione di Competenze ed Impresa in ambito Intelligenza Artificiale.
Le slide di Marco sono a questo link (pdf 1.5M)
Il meetup DataScienceSeed fa parte delle iniziatove dell’associazione IAML, Italian Association for Machine Learning
Questo incontro è possibile anche grazie al supporto di

![]()


























 Video by Wonderland Productions
Video by Wonderland Productions 



